Comment créer une bonne API Web - Partie 3
Posté le 29 novembre 2020 dans Programmation • Tags: api, graphql, rest, javascript, nodejs • Temps de lecture: 22 min
Bonjour,
Cet article fait partie d'un ensemble:
Il y a quelques années de cela, j'ai souhaité résoudre un problème que j'ai depuis longtemps avec les API REST: comment bien normaliser les tris, les projections, et les filtres. En effectuant mes recherches je suis tombé sur deux frameworks qui permettent de résoudre le problème des projections.
Qu'est qu'une API Falcor
Je ne vais parler que succinctement de Falcor. C'est un framework que je n'ai pas utilisé mais j'ai tout de même été très intéressé par ce dernier et je vais écrire quelques lignes sur ce Framework.
Pour plus d'informations, vous pourrez vous référer à la documentation.
Pour reprendre les explications de la documentation, Falcor est un middleware de votre application qui permet d'interroger des ressources au format JSON sur le serveur, comme votre application le ferait sur des données en mémoire.
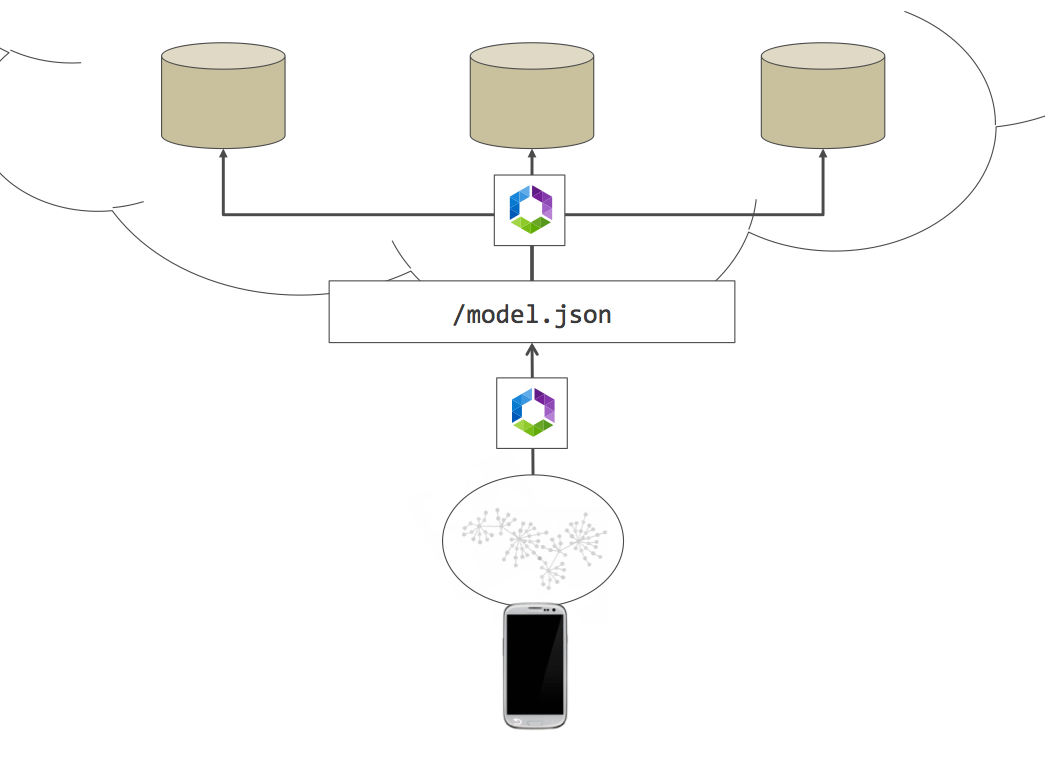
La requête envoyée alors au serveur ne contient que les champs demandés par le client, ce qui permet au serveur de sélectionner les champs et de ne retourner que ces champs. De plus le serveur peut n'exposer qu'un seul modèle contenant toutes les ressources (que ce soit pour retourner des listes ou des items particuliers).
En une seule requête, le client peut alors demander l'ensemble des données dont il a besoin, et l'afficher.
Nous n'avons plus alors le dilemne "faut-il créér une sous-resource, ou l'intégrer dans la ressource actuelle ?". Du point de vue du client: plus besoin d'effectuer plusieurs requêtes complexes pour récupérer plusieurs ressources, un seul appel suffit.
/model.json?paths=["user.name", "user.surname", "user.address"]
GET /model.json?paths=["user.name", "user.surname", "user.address"]
{
user: {
name: "Frank",
surname: "Underwood",
address: "1600 Pennsylvania Avenue, Washington, DC"
}
}
Le Router falcor côté serveur, s'occupe alors de dispatcher les différentes parties demandées par le client à différents backends, qui peuvent
alors répondre indépendament les uns des autres.
Falcor va s'occuper alors d'aggréger le résultat.
 .
.
Pour récupérer des données depuis le front:
// ask for name and age of user with id = 5
model.get("users[5]['name','age']");// which will eventually return something like
{
"users": {
"5": {
"name": "John Doe",
"age": 33
}
}
}// you can also ask for ranges
model.get("users[5..7].name);// which eventually returns the following
{
"users": {
"5": { "name": "John Doe" },
"6": { "name": "Jane Doe" },
"7": { "name": "Mary Poppins" }
}
}
L'avantage de ce framework, est qu'il permet de simplifier l'écriture des projections et de la partie lecture d'une API.
Ce pourquoi je n'ai pas choisi ce framework vient en deux choses:
- Il est disponible principalement pour Javascript (NodeJS + Front) ; Il existe une version Java même qui n'a pas été mise à jour depuis 2018 et donc je ne retrouve pas les sources.
- J'ai trouvé mieux en GraphQL.
Qu'est qu'une API GraphQL
Venant du constat que Falcor répondait à mon besoin de pouvoir normaliser la projection mais avec quelques limites, j'ai continué mes recherches et je suis tombé sur GraphQL.
GraphQL répond à la même problèmatique: pouvoir laisser au client choisir la projection qu'il souhaite des données. Comme Falcor, GraphQL permet de ramener plusieurs ressources en une requête. Et comme Falcor, GraphQL permet d'aggréger le résultat côté serveur de façon asynchrone.
L'avantage de GraphQL sur Falcor est que GraphQL est une norme écrite par Facebook alors que Falcor est une librairie Javascript. De la norme GraphQL, découle une implémentation officielle en Javascript mais aussi dans plein d'autres languages.
Par contre GraphQL n'est qu'un language de requête. Il ne décrit pas comment doit être transportée la requête sur le réseau, ni comment doit être transférée la réponse. Seul le contenu est normalisé. Les frameworks sont tout de même compatibles entre eux.
Par contre cela permet d'utiliser GraphQL pour autre chose que des requêtes réseaux. On pourrait envisager de faire un service qui ne répond qu'à des requêtes GraphQL. Ce service est alors rattaché au contrôleur pour une exposition mais aussi directement appelable en interne par d'autres services. Cela pourrait permettre de faire une couche d'abstraction interne.
Il existe plusieurs frameworks ajoutant la couche de transport à GraphQL. Dans la suite je parlerai d'une des implémentations qui se nomme Apollo.
Maintenant passons au vif du sujet.
Query - Introduction
Le système de requête de graphql permet au client de décrire ce qu'il souhaite récupérer. C'est au client de décider des éléments qu'il souhaite et de construire sa requête.
Voici un exemple de requête de requête:
query Dashboard {
queueStats {
waiting
active
failed
lastExecution
nextWakeup
}
diskUsageStats {
currentRepartition {
host
total
}
currentSpace {
size
used
}
}
}
Derrière chaqu'un des membres ci-dessus, on peut retrouver un resolver. Un resolver c'est l'équivalent du contrôleur pour une API REST. C'est le resolver qui va récupérer les informations demandées par le client (arguments, projection, ...) et les transférer au service.
Il nous faudra alors faire un lien entre le schéma et ces resolvers. Pour le client, peu importe qu'il faille, pour une requête, exécuter en tâche de fond 1 resolver ou 10 resolver. Le client n'a pas besoin de le savoir.
Imaginons que dans l'exemple ci-dessous le champs nextWakeup nécessite un calcul complexe. Il suffit de créer un resolver qui
effectue ce calcul.
Si jamais le client n'a pas besoin de l'afficher et du coup, ne le demande pas, alors ce calcul complexe ne sera pas fait et c'est du temps
de traitement gagné sur le serveur.
En REST, un champ qui nécessite un calcul complexe et soit
- inclus dans la resource et donc toujours effectué quelque soit le besoin du client
- séparé dans une ressource séparée, au risque de complexifier l'API et de demander au client de faire plusieurs requêtes si nécessaire (surtout si on a plus d'un champ calculé).
Nommer ces requêtes
Dans l'exemple ci-dessus, on peut remarquer que la requête possède un nom. C'est une bonne pratique de toujours nommer l'opération
(ici Dashboard). Nommer les opérations permet de :
- mettre plusieurs opérations nommées dans une seule requête.
- mais aussi de mieux tracer et débugger les requêtes côté serveur dans les logs.
Query - Coté serveur
Côté serveur nous allons commencer par décrire le schéma que pourra alors utiliser le client pour effectuer ces requêtes. Par exemple :
scalar Date
"""
Define the state of the queue
"""
type QueueStats {
"""
Number of task waiting in queue
"""
waiting: Int!
"""
Number of task active in queue
"""
active: Int!
"""
Number of task that have failed
"""
failed: Int!
"""
Date of the last execution
"""
lastExecution: Date!
"""
Date of the next wakeup
"""
nextWakeup: Date!
}
type DiskCurrentRepartition {
host: Int!
total: Int!
}
type DiskCurrentSpace {
size: Int!
used: Int!
}
type DiskUsageStats {
currentRepartition: [DiskCurrentRepartition!]!
currentSpace: DiskCurrentSpace!
}
type Query {
queueStats: QueueStats!
diskUsageState: DiskUsageStats!
}
On peut remarquer plusieurs choses:
- Tous les champs ont un type (String, Int, Float, Array, Date)
- Il est possible de créer de nouveaux types simples, scalaires: par exemple champ de type Date.
- Il est possible de créer de nouveaux types complexes, ce qui en fait nos structures.
- Le point d'exclamation permet d'indiquer que le champ retourné ne sera jamais null (et donc le client peut compter dessus s'il le souhaite).
- Il est possible de mettre de la documentation au niveau de chaque champ mais aussi au niveau des types.
Ce schéma (qui peut aussi être généré à l'aide d'annotations en Typescript, par exemple) sert également de documentation (un peu comme swagger).
Il est alors possible d'utiliser des outils comme
pour générer de la documentation mais aussi des outils comme
- GraphQL Playground
- GraphiQL qui sont des IDE permettant de faire des requêtes (avec documentation et auto-completion).
Une fois le schéma écrit, il peut être communiqué aux équipes front (si les équipes sont séparées). Pendant que l'on développe alors le front, côté serveur on peut alors implémenter le schéma.
Pour implémenter le schéma ci-dessus, nous allons écrire un resolver (en Javascript pour l'exemple).
const resolvers = {
Query: {
queueStats() {
return getQueueStats();
},
async diskUsageState() {
return await getDiskUsageState();
},
},
};
Un resolver peut pour un champ:
- retourner une valeur
- retourner une fonction qui retourne la valeur
- retourner une fonction qui retourne une promesse avec la valeur
Ainsi imaginons que la méthode getQueueStats() retourne l'objet suivant, dans lequel il manque nextWakeup et lastExecution :
{
"waiting": 0,
"active": 2,
"failed": 0
}
Il est possible d'écrire un resolver :
const resolvers = {
Query: {
queueStats() {
return getQueueStats();
},
async diskUsageState() {
return await getDiskUsageState();
},
},
QueueStats: {
lastExecution(parent /*: QueueStats */) {
const { active } = parent; // Ici pour l'exemple on peut récuperer un attribut de parent.
return getLastExecution();
},
nextWakeup() {
return getNextWakup();
},
},
};
Il est alors possible de créer son schéma en pensant à comment le client va intéroger ce dernier, et lors de l'implémentation ajouter des structures complexes qui sont issues du calcul synchrone ou asynchrone des données.
Query - Nullable
On a vu précédement qu'on pouvait utiliser le point d'exclamation pour indiquer qu'un champ ne sera jamais NULL. Cela peut avoir des avantages pour le client mais cela a aussi de grandes implications côté serveur.
Par défaut pour GraphQL, tous les champs sont nullable par défaut. En effet, si un resolver n'arrive pas à récupérer la donnée (erreur côté serveur, back HS, problème de base de données, problème réseau, droits d'accès différents selon les champs ...), le serveur pourra retourner NULL à la place de la valeur (et une erreur en parallèle du json). Cela permet au client une vue partielle même si certains services ne sont pas disponibles.
Si le champ ne peut pas être null, alors le json ne pourra pas du tout être envoyé et c'est la requête complète qui est en ereur.
C'est pour cela qu'en GraphQL chaque champ peut, par défaut, obtenir la valeur null.
Lors de la conception d'un schéma GraphQL, il faut utiliser la possibilité de rendre le champ non nullable avec réflexion et uniquement pour les champs dont on souhaite garantir la non nullité.
Query - Ajout d'arguments
query HeroNameAndFriends($episode: Episode) {
hero(episode: $episode) {
name
friends {
name
}
}
}
Il est possible en GraphQL de définir certain champs comme ayant des paramètres. Ils seront alors passés au resolver. Il est également possible d'avoir des paramètres à différents niveaux du schéma (pas seulement au niveau le plus haut).
Le passage de paramètres permet d'écrire son opération une fois et ensuite de l'appeler avec des paramètres. C'est important de définir les saisie utilisateurs comme des paramètres pour éviter les injections GraphQL (comme en SQL, ou autre).
Règle n°1: Ne jamais faire confiance à l'utilisateur.
Query - Création d'alias
Si on souhaite récupérer plusieurs valeurs d'un attribut en fonction de ses paramètres, il est possible de le demander plusieurs fois et de lui associer un alias.
query aliasQuery {
empireHero: hero(episode: EMPIRE) {
name
}
jediHero: hero(episode: JEDI) {
name
}
}
Dans le JSON résultant, on retrouve alors les deux attributs empireHero et jediHero qui sont tous les deux issus du membre hero avec un paramètre
différent. Cela peut aussi être utilisé pour simplement renommer un champ.
Query - Fragment
Les fragments permettent de factoriser et de créer des morceaux de requêtes réutilisables.
# Dans le fichier FragmentJob.graphql
fragment FragmentJob on Job {
id
state
failedReason
data {
host
}
}
# Dans le fichier QueueTasks.graphql
#import "./FragmentJob.graphql"
query QueueTasks($state: [String!]) {
queue(state: $state) {
...FragmentJob
}
}
Le Fragment FragmentJob peut alors être réutilisé dans différentes requêtes, voir même plusieurs fois dans la même requête.
Query - Gestion de version
J'en parlais dans les articles précédents, il existe plusieurs manières de versionner une API. GraphQL n'y échappe pas. On peut:
- ajouter un numéro de version dans le path de l'url, dans le nom de l'hôte, dans un header http.
- ou décider de gérer une seule API rétro-compatible où on décommissionne au fur et à mesure les champs.
Les créateurs de GraphQL partagent leur opinions. Comme c'est le client qui décide
des champs qu'il souhaite rappatrier, toute évolution du schéma ajoutant de nouveaux attributs ne pose aucun problème et ne surchargera pas
plus le client.
Les suppressions doivent passer par une phase d'obsolescence ou les attributs sont marqués avec l'annotation @deprecated et leur décommissionnement
automatique.
Afin de pouvoir facilement décommissionner des attributs, le mieux est de savoir quels attributs sont utilisés ou non. La librairie Apollo permet de se connecter au studio d'appolo et de visualiser l'utilisation des attributs. Savoir qu'un attribut n'est pas utilisé permet de le décommissionner ou de le modifier. Bien sûr et malheureusement cette partie n'est pas open source. Je n'ai pas encore trouvé de dashboard OpenSource permettant d'analyser l'utilisation d'un champ.
Ce qui est important c'est d'avoir une politique de versionning.
Query - Pagination
GraphQL n'a pas défini de règle concernant la pagination car il y a plein de manières de la gérer. Pour des listes contenant peu d'éléments, il n'y a par exemple pas lieu de gérer la pagination.
Quand on envisage la pagination, on peut en faire une par page avec un nombre d'éléments à passer (skip), ou une basée sur l'id du premier élément à afficher.
Il existe également des patterns que l'on peut utiliser pour ne pas réinventer une nouvelle facon de faire.
Par exemple l'un de ses patterns s'appele Connections et des librairies comme Relay savent comment gérer automatiquement ce pattern.
Dans le pattern Connections, nous retrouvons les notions:
- En entrée
- nombre d'éléments à récupérer
- le curseur à partir duquel retourner les données
- En sortie
- Le nombre d'éléments total
- Les informations sur la page comme le prochain curseur et si on a une page suivante
- Les différents éléments de la page (avec le curseur associé)
{
hero {
name
friendsConnection(first: 2, after: "Y3Vyc29yMQ==") {
totalCount
edges {
node {
name
}
cursor
}
pageInfo {
endCursor
hasNextPage
}
}
}
}
On peut retrouver la spécification de ce modèle de pagination sur le site de relay.dev
Query - Cache - Control
Contrairement au REST où on peut peut utiliser les header HTTP, pour contrôler le cache, en GraphQL une requête peut avoir des limites d'âge différentes sur les différentes resources appelées. Il faut donc trouver d'autres moyens de gérer le cache.
C'est pour moi un des points les plus gênants de GraphQL.
Sur le serveur, il y a plusieurs manières complémentaires (à différentes fins) de gérer le cache. Nous allons nous concentrer sur la librairie apollo-server.
La 1ère manière s'apparentant au cache-control des requêtes HTTP peut être utilisée avec la directive @cacheControl ou au niveau du resolver. Elle ne permet pas de cacher directement la donnée
mais de donner une indication au client sur combien de temps cette donnée peut-être cachée. Si la librairie utilisée côté client est également apollo elle utilisera alors ces indications pour
gérer le cache de la donnée (et donc ne pas ré-effectuer la requête.)
scalar Date
"""
Define the state of the queue
"""
type QueueStats @cacheControl(maxAge: 60) {
"""
Number of task waiting in queue
"""
waiting: Int!
"""
Number of task active in queue
"""
active: Int!
"""
Number of task that have failed
"""
failed: Int!
"""
Date of the last execution
"""
lastExecution: Date! @cacheControl(maxAge: 3600)
"""
Date of the next wakeup
"""
nextWakeup: Date! @cacheControl(maxAge: 3600)
}
Je vous invite à lire la documentation d'apollo qui contient énormément d'informations. Cette méthode permet d'ajouter des header http pour cacher les requêtes dans un CDN intérmédiaire, ou dans une base redis attachée au serveur, ou dans le cache navigateur, voir également au niveau même du client.
Query - Cache - DataLoader
La 2nd méthode de cache consiste à l'utilisation de DataLoader. L'ajout d'un dataloader a pour but de cacher le temps d'une requête les différents éléments pour éviter de multiplier les appels. Le but n'étant pas de réellement faire du cache mais plutôt de pouvoir traiter une requête batch le plus rapidement possible.
Imaginons par exemple la requête suivante :
query TestDataLoader {
backups {
id
startDate
endDate
user {
firstName
lastName
}
}
}
Dans le cas présent, on souhaite récupérer les backups, mais également pour chaque backup récupérer l'utilisateur. Si l'utilisateur est le même pour chaque backup, on se retouve alors à charger l'utilisateur plusieurs fois. Le fait d'utiliser un dataloader permettra dans le cas présent de ne les charger qu'une fois.
Pour utiliser le système de data loader, on peut utiliser la bibliothèque du même nom: [https://github.com/graphql/dataloader](Github: graphql/dataloader). Il nous faut alors créer un dataloader pour un type d'objet.
import DataLoader from "dataloader";
const userLoader = new DataLoader((keys) => service.getUsers(keys));
Ensuite dans les resolvers, au lieu de récupérer les utilisateurs directement à partir du service, on utilise le data loader pour récupérer la valeur :
const resolvers = {
async backups() {
return service.find();
},
Backup: {
async user(ctx, { id }) {
return await userLoader.load(id);
},
},
};
Dataloader n'est par contre pas fait pour être utilisé en tant que cache applicatif et ne remplace donc pas un memcached ou un redis.
Query - Batch
Apollo côté client propose de pouvoir faire du batching de requêtes. Cela consiste à attendre un léger laps de temps pour regrouper en une seule requête plusieurs requêtes.
Attention néanmoins, mettre en place le batching de requêtes implique:
- qu'on attend (pas très longtemps) pour envoyer les requêtes
- qu'on attend l'aggrégat des réponses avant de les recevoir
- qu'on ne bénéficie pas du multiplexing des requêtes de HTTP/2.
Il est alors conseillé d'abord de faire d'autres types d'optimisations (comme utiliser les requêtes persistentes, un cache dans un CDN des réponses, utiliser HTTP/2 jusqu'au NodeJS) avant de mettre en place le système de batch.
Si vous voulez le mettre tout de même en place, vous pouvez regarder la documentation d'Apollo sur ce sujet.
Query - Transfert réseau
Pour une API Web, les requêtes et les réponses sont transférées en utilisant le protocole HTTP. Pour améliorer les performances il est possible d'utiliser plusieurs méthodes:
- Comme en REST, activer la compression GZIP coté serveur, permet de réduire les flux réseaux
- Utiliser les requêtes persistentes (stocké coté serveur) : https://www.apollographql.com/docs/apollo-server/performance/apq/
- Utiliser les fragments pour réutiliser certaines parties des requêtes qui peuvent se répéter.
- Utiliser HTTP/2 et le multiplexing des requêtes. Faire une seule grosse requête peut être contre-productif avec HTTP/2. En effet il faut attendre la fin de la résolution de l'ensemble des resolvers côté serveur avant d'avoir la réponse. Faire plusieurs requêtes peut permettre d'avoir certaines parties de la requête plus vite. De plus HTTP/2 permet de mieux paralléliser les requêtes. Il faut donc trouver le bon nombre de requêtes à executer pour avoir les meilleurs performances.
Mutation
Nous avons énormément parlé de toute la partie requête de GraphQL. GraphQL permet également de faire des modifications via des mutations.
Une mutation est similaire à une requête :
mutation CreateBackup($backup: CreateBackupInput!) {
createBackup(backup: $backup) {
statusCode
message
error
errorCode
backup {
id
state
user {
id
}
}
}
Nous retrouvons la partie input, et la partie query (sur la réponse). Alors que généralement sur query on va retrouver des types primitifs en paramètres, on va plutôt retrouver en paramètre d'une mutation un objet de type Input. Sur le résultat le fonctionnement est lui le même que sur une Query.
Nous pouvons d'ailleurs utiliser les mêmes resolvers sur les réponses que dans les queries (et ainsi récupérer l'utilisateur de la backup de la même manière).
En bonne pratique, ce que nous pouvons retrouver sur les mutations sont:
- Ne pas renvoyer l'objet créé/modifié directement. Renvoyer un objet permettant à l'utilisateur de récupérer l'erreur fonctionnelle ou l'objet selon le cas. Cela permettra de faire évoluer plus facilement le résultat si nécessaire.
- De la même manière, même si la mutation a besoin de très peu de paramètres en entrée, il vaut mieux créer un objet de type
inputafin de passer les paramètres. Ceci également afin de pouvoir évoluer facilement avec l'API au fur et à mesure des évolutions. - Eviter pour le paramètre principal ou la sortie principale de réutiliser un objet. Il vaut mieux en créer un propre à la
mutation. - Contrairement à REST, les
mutationsGraphQL ressemblent plus à du RPC. Il vaut mieux alors éviter de penser ressources mais plutôt actions. Quels sont les actions que l'on souhaite pouvoir faire depuis l'IHM.
Il ne faut pas hésiter à découper ces actions en petites actions que l'utilisateur peut choisir d'appeler ou non (il est possible d'appeler plusieursmutationsen un seul appel). - Penser les
mutationsen fonction des appels de vos clients.
Si on reprend le schéma suivant:
input InputUser {
name: String!
}
input CreateBackupInput {
host: String!
user: InputUser!
}
type Backup {
host: String!
id: Int!
startDate: Date
endDate: Date
user: User
}
type User {
name: String
backups: [Backup!]
}
type CreateBackupResponse {
statusCode: Int!
message: String
error: String
errorCode: String
backup: Backup
}
Contrairement aux paramètres de sortie, il n'est pas possible sur les input de faire des dépendances circulaires. Un input doit donc être lié à l'action faite
par la mutation.
Cela veux dire aussi qu'il n'est pas possible de réutiliser un type de sortie en input pour l'entrée. Le point d'exclamation n'est plus un indicateur de non nullité
mais un indicateur de paramètre obligatoire.
Lors de la conception des ces inputs il faut d'ailleurs penser à plusieurs choses:
- Certain champs en sortie dans un type sont là pour representer un calcul ou un état qui fait sens mais que l'utilisateur ne peut pas modifier. Il ne faut donc pas le mettre en entrée.
- Un paramètre qui peut être non nul en sortie n'est pas forcément obligatoire en entrée (et inversement).
Pour une application possédant beaucoup de formulaires et d'écrans de modifications ou d'actions, il peut être donc compliqué d'écrire les requêtes et les mutations associées.
Il peut peut-être être intéressant d'utiliser un transpiler comme graphql-s2s qui permet de simplifier certaines choses dans l'écriture du schéma. Lors de son utilisation sur un projet possédant un gros schéma, il a permis la reprise d'une API Rest existante plus facilement.
Il permet entre autres:
- de ne pas répéter les champs de l'interface lors de l'héritage d'un type.
- de définir des types génériques (qui à la compilation créeront des vrais types).
Subscription
Un des points que j'adore avec GraphQL c'est la facilité d'implémentation qu'apporte Apollo avec les Subscritpions. Quand on souhaite remonter des informations
du serveur au client, on peut mettre en place des WebSockets ou des Server-Side-Events. Il faut alors définir un potocole entre le client et le serveur.
GraphQL utilise de façon transparente une WebSocket dans le cadre des souscriptions. L'avantage c'est que le protocole est le même que pour les query. On effectue une demande et au lieu d'avoir une réponse, une fois, on reçois les mise à jours sur la souscription.
Cela permet de mettre en place facilement des pages dynamiques qui évoluent sans actions utilisateurs (progression, chat, ...) sans se casser la tête.
Pour définir une souscription on peut utiliser une requête comme celle-ci:
#import "./FragmentJob.graphql"
subscription QueueTasksJobUpdated {
jobUpdated {
...FragmentJob
}
}
Dans l'exemple ci-dessous je réutilise le fragment d'un job défini dans une query. La souscription dans apollo va automatiquement mettre à jour le résultat et rafraichir l'IHM.
Par exemple avec vue cela donne (cf la doc de vue-apollo):
apollo: {
tags: {
query: TAGS_QUERY,
subscribeToMore: {
document: gql`subscription name($param: String!) {
itemAdded(param: $param) {
id
label
}
}`,
// Variables passed to the subscription. Since we're using a function,
// they are reactive
variables () {
return {
param: this.param,
}
},
// Mutate the previous result
updateQuery: (previousResult, { subscriptionData }) => {
// Here, return the new result from the previous with the new data
},
}
}
}
La requête initiale est faite grâce à TAG_QUERY, puis toutes les mises à jours se font via la souscription. L'IHM est alors automatiquement mise à jour.
Conclusion
GraphQL est super puissant et facilite l'écriture d'API et son utilisation par des clients. Par contre la montée en compétence pour faire du GraphQL est un peu plus élevée que pour faire du REST (Bien qu'il n'est pas facile de faire du bon REST).
Il peut toujours être utile de proposer des API Rest en plus des API GraphQL. Pour par exemple permettre au client de choisir ce qu'il souhaite utiliser ou même par exemple pour des cas d'usage particuliers. (Par exemple le téléchargement/l'upload d'un document binaire est plus facile en REST que en GraphQL).