Parseur XML
Posté le 31. May 2009 dans Programmation
Bonjours à tous,
L'utilisation des fichiers XML est, à ce jour, un fait dans la plupart des logiciels et est fortement à la mode. Une entreprise qui ne fait pas un peu de XML est souvent has-been. On utilise alors le XML à bon ou mauvais escient.
Avantages / Inconvénients
Pourquoi utiliser les fichiers XML ? Les fichiers XML sont, pour commencer, des fichiers textes, il seront donc toujours lisibles, ce qui garantit une meilleur pérennité de l'information. Les fichiers XML sont structurés hiérarchiquement et suivent une syntaxe stricte. Ainsi le XML est lisible informatiquement par les différents langages de programmation existant, pour organiser vos données, en utilisant différents niveaux. Les fichiers XML peuvent être commenté ce qui peut améliorer la lisibilité pour un humain.
Le gros inconvénient du XML est sa verbosité. Pour chaque noeud dans la hiérarchie, il y a une balise de début, et une balise de fin contenant le nom de la balise. Le fichier est moins compact que s'il avait été écrit en binaire. Cela peut poser des problèmes comme alourdir les communications réseaux (ex: pour les webservices). Le fichier est aussi plus long à lire qu'un fichier binaire et peut contenir des erreurs.
Si le fichier n'a pas besoin d'être hiérarchique, il est possible d'utiliser une structure de fichier INI pour ses données.
Nous nous arrêterons là pour les avantages/inconvénients. L'utilisation ou non d'un fichier XML est ensuite une question (besoin, éthique, ...) à se poser pour ses données et la nécessité de pouvoir les lire autrement que par le programme lui-même.
Performance des parseurs.
Je me suis amusé à effectuer le test de lecture de différents fichiers de donnée au format XML de taille différentes par une variété de parseur XML en construisant si possible un arbre DOM. Le but est donc de créer un objet par noeud/attribut du fichier XML et de reconstituer la hiérarchie.
Les parseurs choisis pour ce test sont :
- QtXml : Le module XML de la librairie Qt (de la société Nokia)
- LibXml2 : Une librairie C permettant de faire du parsing XML en utilisant DOM ou SAX
- LibExpat : Un parseur orienté flux (plus proche de la méthode SAX que du DOM)
- SCEW : Un parseur basé sur Expat générant un arbre DOM (donc un peu plus comparable aux autre parseur).
- TinyXML : Encore un autre parseur XML
- Xerces-C++ : Le parseur XML d’Apache
- Oracle XML Parser : Le parseur d’Oracle propriétaire utiliser dans le serveur d’application.
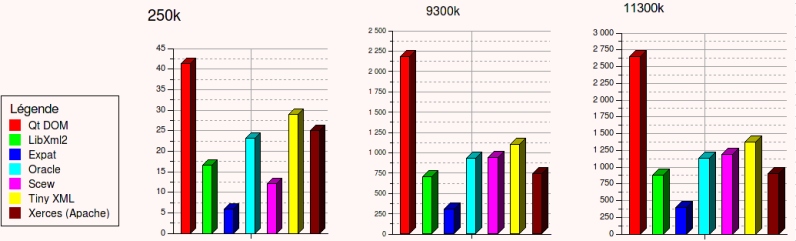
Pour faire cette suite de benchmark1, j’ai utilisé la librairie QTestLib de Nokia/Qt. Je vous offre donc en avant première le résultat de ce test :
| 250k | 9300k | 11300k | |
|---|---|---|---|
| Qt DOM | 41,42 ms | 2184,34 ms | 2648,71 ms |
| LibXML2 | 16,55 ms | 710,09 ms | 874,42 ms |
| Expat (SAX) | 5,95 ms | 312,02 ms | 393,58 ms |
| Oracle | 23,24 ms | 928,93 ms | 1135,86 ms |
| Scew | 12,05 ms | 944,37 ms | 1184,46 ms |
| Tiny XML | 28,91 ms | 1101,8 ms | 1369,8 ms |
| Xerces (Apache) | 25,03 ms | 742,22 ms | 904,62 ms |
La conclusion de ce résultat signifie que le parseur inclu dans Qt (pour la construction d'un arbre DOM) est très lent ;). Mais pour une utilisation dans une interface graphique, sur de petits fichiers, ne devrait pas poser de problème.
Enfin le parseur le plus rapide (pour les gros fichiers) est Libxml2. Le parseur C d'oracle, bien que propriétaire n'a rien d'exceptionnel (si on compte avec les problèmes présenté également ci-dessous). Peut-être que la version Java est elle plus performante.
Vous pouvez retrouver quelques graphiques ci-dessous :
Le source du benchmark
Voici de suite :
Pour la partie utilisation du Parseur Oracle, il a fallut contourner plusieurs petits problèmes. Ceci est la joie des librairies propriétaires bien documentées.
Compilation avec le XDK 9
Lors de la compilation avec le XDK 9, l'application ne dépasse pas le stade du linkage. Les méthodes sont pourtant bien dans les includes. De plus les librairies sont bien précisées pour le linkage.
La définition faite dans le projet est :
XDKPATH = xdk9
XDK_LIB = -lxmlg9 -lxml9 -lxsd9
ORA_LIB = -lcore9 -lnls9 -lunls9 -lcore9 -lnls9 -lcore9
NET_LIB = -lnsl
LIBS += -L$$XDKPATH/lib $$XDK_LIB $$ORA_LIB $$NET_LIB -lpthread
INCLUDEPATH += $$XDKPATH/xdk/includeA la suite de ça, lors de la phase de compilation, on se retrouve avec les messages d'erreurs suivants :
g++ -Wl,-O1 -o xmlparserbenchmark libxml2parser.o expatparser.o xercescppparser.o oracleparser.o qtparser.o scewparser.o tinyparser.o tinyxml.o tinystr.o tinyxmlerror.o tinyxmlparser.o xmlparserbenchmark.o moc_xmlparserbenchmark.o -L/usr/lib -lxml2 -lexpat -lxerces-c -Lxdk9/lib -lxmlg9 -lxml9 -lxsd9 -lcore9 -lnls9 -lunls9 -lcore9 -lnls9 -lcore9 -lnsl -lpthread -Lscew/scew -lscew -lQtTest -lQtXml -lQtGui -lQtCore -lpthread
oracleparser.o: In function `parseWithOracleParser(QString const&)':
oracleparser.cpp:(.text+0x82): undefined reference to `XMLParser::xmlinit(unsigned char*, void (*)(void*, unsigned char const*, unsigned int), void*, xmlsaxcb*, void*, unsigned char*)'
oracleparser.cpp:(.text+0xa8): undefined reference to `XMLParser::xmlparse(unsigned char*, unsigned char*, unsigned int)'
oracleparser.cpp:(.text+0x2b4): undefined reference to `XMLParser::getDocumentElement()'
oracleparser.cpp:(.text+0x2ca): undefined reference to `XMLParser::xmlterm()'J'ai alors essayé de recompiler les exemples de démonstrations mais là, même problème ...
Compilation avec le XDK 10
Avec cette version du XDK, nous avons le droit à deux problèmes. Le premier est une grosse fuite mémoire (si on écrit le programme tel que décrit dans la démo), et à un problème d'initialisation du parseur.
Le code permettant de parser le fichier XML et de générer l'arbre DOM ressemble à ceci :
CXmlCtx * ctxp = 0;
try {
ctxp = new CXmlCtx();
} catch( XmlException & e ) {
unsigned ecode = e.getCode();
QFAIL( qPrintable( QString("Failed to initialize XML context, error %1").arg( ecode ) ) );
}
Factory<CXmlCtx,xmlnode> * fp = 0;
try {
fp = new Factory<CXmlCtx,xmlnode>( ctxp );
} catch( FactoryException & fe ) {
unsigned ecode = fe.getCode();
QFAIL( qPrintable( QString("Failed to create create parser, error %1").arg( ecode ) ) );
}
DOMParser<CXmlCtx,xmlnode> * parserp = 0;
try {
parserp = fp->createDOMParser( DOMParCXml, NULL );
} catch( FactoryException & fe ) {
delete fp;
unsigned ecode = fe.getCode();
QFAIL( qPrintable( QString("Failed to create parser, error %1").arg( ecode ) ) );
}
const char * fname = filename;
FileSource * isrcp = new FileSource( (oratext*) fname );
try {
DocumentRef<xmlnode> * docrefp = parserp->parse( isrcp, FALSE );
if( docrefp == NULL ) {
QFAIL( qPrintable( QString("NULL document") ) );
return;
}
xmlnode * np = docrefp->getDocumentElement();
if( np == NULL ) {
QFAIL( qPrintable( QString("Empty document") ) );
return;
}
docrefp->markToDelete();
delete docrefp;
} catch( ParserException & pe ) {
delete parserp;
delete isrcp;
delete fp;
unsigned ecode = pe.getCode();
QFAIL( qPrintable( QString( "Failed to parse the document, error %1").arg( ecode ) ) );
}
// delete parserp;
// delete isrcp;
// delete fp;
// delete ctxp;Le premier problème se situe lors de la suppression du contexte
(dernière ligne, en commentaire). Si cette ligne est exécutée, alors
nous avons une grosse erreur de segmentation. J'ai le problème, quels
que soient les delete que je fais avant.Même en faisant le maximum de
delete (soit parserp, isrcp, fp), le fait de ne pas supprimer le
context (ctxp), fait qu'au bout de plusieurs itérations, nous avons une
bonne fuite mémoire2.
Vient ensuite le second problème, celui des erreurs d'intialisation. Si le parseur est lancé plusieurs fois de suite, alors l'application affiche les erreurs suivantes à l'écran :
LPX-00202: Message 202 not found; No message file for product=XDK, facility=LPX
FAIL! : XmlParserBenchmark::oracleParser(file250k.xml) Failed to parse the document, error 202
Loc: [oracleparser.cpp(73)]Aucune explication sur le pourquoi. Parfois ça marche, parfois non... Pour contourner le problème, j'ai forké le parseur pour l'exécuter isolé du reste.
pid_t pid = fork();
if( pid > 0 ) {
waitpid( pid, (int*)0, 0 );
} else if( pid == 0 ) {
if( ! filename.isEmpty() )
parse( qPrintable( filename ) );
exit( 0 );
} else {
QFAIL( "Cannot fork" );
}