Woodstock Backup v2.0.0 - La réécriture complète en Rust
Posté le 26 avril 2026 dans Woodstock • Tags: woodstock, backup, sauvegarde, rust, grpc • Temps de lecture: 21 min
Bonjour à tous,
Six ans. Il m'aura fallu six ans entre la première version de Woodstock Backup et cette v2. Si vous m'aviez dit en 2020 que je passerais la moitié de la décennie à réécrire trois fois le même logiciel de sauvegarde... j'aurais quand même foncé tête baissée. C'est ma façon de faire. Me voilà donc avec une version 2 stable, entièrement réécrite en Rust, qui tourne en production sur ma petite infrastructure depuis plus d'un an. Et je suis vraiment content du résultat. 😄
Pour ceux qui me lisent depuis longtemps, voici un récapitulatif des articles qui ont précédé celui-ci :
| Article | Date | Sujet |
|---|---|---|
| Woodstock Backup v1.0.0 | 2020-09-20 | Présentation du projet, prototype TypeScript + rsync |
| Woodstock Backup - Btrfs | 2021-01-12 | Abandon de Btrfs, écriture d'un pool custom |
| Woodstock Backup - Protocole et Langage de sauvegarde | 2021-04-18 | Protocole gRPC maison |
| Woodstock Backup - Optimiser Node.js avec Rust | 2023-05-10 | NAPI-RS et bindings Rust pour réduire la consommation mémoire |
| Woodstock Backup - Reverse engineering de BackupPC | 2024-05-07 | Migration du pool BackupPC vers Woodstock |
Pour les nouveaux, je résume : Woodstock Backup est mon logiciel de sauvegarde personnel, centralisé, qui sauvegarde toutes les machines de mon réseau local et mes serveurs distants sur un NAS. L'idée de départ était simple. Le résultat est... un peu plus complexe. :)

Le long chemin de 2020 à 2026
Prototype 1 : TypeScript + rsync + Btrfs (2020)
Tout a commencé avec un prototype en TypeScript qui utilisait rsync pour copier les fichiers et Btrfs pour les snapshots incrémentaux. L'idée était élégante sur le papier : rsync calcule le delta, Btrfs déduplique, tout le monde est content.
En pratique, je me suis rapidement retrouvé avec des problèmes de stabilité de Btrfs lorsque le nombre de snapshots devient élevé et que le système de fichiers approche de la saturation. J'en ai parlé en détail dans mon article sur Btrfs. En résumé : abandonné.
Prototype 2 : TypeScript + gRPC + pool custom (2021)
L'abandon de Btrfs m'a forcé à écrire mon propre pool de stockage basé sur le principe de Content-Addressable Storage (CAS) : chaque bloc de fichier (chunk) est identifié par son hash, et si deux fichiers partagent des blocs identiques, ces blocs ne sont stockés qu'une seule fois. La déduplication est donc native.
Pour transférer les fichiers entre les machines à sauvegarder et le serveur, j'ai abandonné rsync et développé mon propre protocole basé sur gRPC. gRPC s'appuie sur HTTP/2, offre une compression et un TLS natifs, et les bibliothèques existent pour tous les langages. Parfait.
Ce prototype, toujours en TypeScript, fonctionnait. Mais le moteur JavaScript de Node.js a ses limites. En particulier, la représentation en mémoire des objets JavaScript est beaucoup plus gourmande que celle d'un langage compilé. Pour un outil qui doit gérer des millions de fichiers, c'est un vrai problème.
L'ère des bindings Rust (2023)
L'idée de cette phase était séduisante : garder toute la partie cœur en Rust pour les performances, et conserver le TypeScript pour la couche GraphQL et la logique applicative. Rust pour ce qui est critique, TypeScript pour ce qui est lisible et rapide à écrire. C'est ce que j'ai décrit dans mon article de 2023.
Bien sûr, je me trompais. En pratique, il fallait des bindings d'exposition NAPI-RS pour chaque interface entre les
deux langages, des DTOs côté TypeScript qui doublonnaient les structures Rust, et surtout, plus le temps passait, plus
le cœur métier migrait vers Rust — laissant de moins en moins de code côté TypeScript. La complexité était réelle :
gérer des équivalents d'Observable ou du streaming en passant par des bindings NAPI-RS n'est pas trivial, même si
les dernières versions de NAPI-RS ont depuis apporté des solutions à ces problèmes.
Le tout en restant performant malgré le coût du passage par les bindings TypeScript. C'était jouable, mais c'était de la jonglerie.
La migration du pool BackupPC (2024)
En parallèle, j'ai travaillé sur la migration de mon pool BackupPC existant vers le format Woodstock. La première approche envisagée consistait à monter les sauvegardes BackupPC via FUSE et à les lire comme un système de fichiers normal. J'ai finalement opté pour une approche plus directe : lire directement le format interne de BackupPC, ce qui impliquait un travail de rétro-ingénierie non négligeable. La migration a été un succès, et j'ai pu enfin abandonner complètement BackupPC.
La décision de tout réécrire en Rust (2024)
À ce stade, la situation était devenue évidente : la partie TypeScript avait tellement rétréci qu'il ne restait plus grand-chose dedans. Un serveur NestJS (framework Node.js) pour l'API, une interface web en Vue.js, et quelques couches de glue — le reste était déjà en Rust. Maintenir deux écosystèmes pour si peu de code TypeScript n'avait plus aucun sens.
J'ai donc décidé de sauter le pas : supprimer les bindings, réécrire intégralement le backend en Rust. Plus de NAPI-RS, plus de DTOs en double, plus de jonglerie entre deux compilateurs. Du Rust pur, de bout en bout.
Woodstock Backup v2 : la version stable (2026)
La version 2.0.0 est en production depuis plus d'un an maintenant, et je la considère comme stable. Les sauvegardes tournent tous les jours, les restaurations
fonctionnent, et je dors tranquille.
Architecture de Woodstock Backup v2
Vue d'ensemble : le modèle Pull
L'architecture reste fondée sur le modèle pull : c'est le serveur de sauvegarde qui initie les connexions vers les périphériques, et non l'inverse. Cela offre une garantie de sécurité importante : un périphérique compromis ne peut pas écrire de données arbitraires dans le serveur de sauvegarde.
Les composants Rust
L'ensemble de la solution est écrit en Rust. Côté serveur, quatre microservices ; côté client, un démon déployé sur chaque machine à sauvegarder :
| Composant | Déployé sur | Rôle |
|---|---|---|
api_server | Serveur | API REST/GraphQL pour l'interface Vue.js — hors du chemin de sauvegarde |
client_api_server | Serveur | Reçoit les connexions mTLS de ws_client_daemon pour le signalement online/offline |
job_worker | Serveur | Exécute les sauvegardes : connexion gRPC vers ws_client_daemon, transfert des chunks, déduplication |
scheduler | Serveur | Gère le planning, déclenche les jobs selon les règles définies |
ws_client_daemon | Chaque périphérique | Reçoit les connexions de job_worker, crée les snapshots, envoie les chunks |
La gestion des jobs de sauvegarde est assurée par Apalis, qui s'appuie sur Redis/Valkey comme backend de file d'attente. Apalis remplace ici BullMQ, qui remplissait ce rôle dans l'ancienne version NestJS. C'est une architecture simple et fiable, qui permet également de distribuer les workers si un jour l'infrastructure venait à grossir.
Le pool de stockage : CAS Blake3+Zstd
Le cœur du système est le pool CAS (Content-Addressable Storage). Son fonctionnement est le suivant :
- Chaque fichier est découpé en chunks de taille variable.
- Chaque chunk est haché avec Blake3 (un algorithme de hachage moderne, très rapide).
- Si le hash du chunk est déjà présent dans le pool, il n'est pas retransféré ni re-stocké.
- Si le chunk est nouveau, il est compressé avec Zstd avant d'être écrit sur disque.
La déduplication est donc réalisée au niveau des chunks, et non au niveau des fichiers entiers. Cela signifie que si un fichier de 10 Go n'a été modifié qu'à 1 %, seul 1 % sera retransféré et stocké.
Le pool maintient également un compteur de références (refcount) par chunk : quand une sauvegarde est supprimée, les chunks qui ne sont plus référencés sont supprimés du pool. Ce mécanisme de garbage collection permet de garder le pool propre sans intervention manuelle.
Sauvegardes Windows : VSS natif
Depuis la version alpha.57, le client Windows utilise le Volume Shadow Copy Service (VSS) de Windows pour créer
un snapshot cohérent du système de fichiers avant la sauvegarde. Cela permet de sauvegarder des fichiers verrouillés
(comme les bases de données, les fichiers de profil Outlook, etc.) sans erreur.
Plus besoin de rsync, de Cygwin, ou d'outils tiers : le client ws_client_daemon est un binaire Rust natif pour
Windows, compilé avec la cible x86_64-pc-windows-msvc, qui utilise les APIs Win32 directement. C'est
nettement plus propre que l'ancienne approche.
Sauvegardes Linux : snapshots Btrfs
Sur les machines Linux dont le système de fichiers est Btrfs, le client crée un snapshot en lecture seule avant de lancer la sauvegarde. Cela garantit la cohérence des données sauvegardées, même si des fichiers sont modifiés pendant la sauvegarde.
Contrairement au premier prototype qui utilisait Btrfs côté serveur (ce qui causait les problèmes évoqués plus haut), ici les snapshots sont créés côté client et uniquement pour la durée de la sauvegarde. C'est une utilisation beaucoup plus conservative de Btrfs.
Les défis techniques
Le refcounting : un problème de cohérence
Le plus grand défi de cette réécriture a été l'implémentation correcte du compteur de références du pool CAS.
Le problème est le suivant : lorsqu'une sauvegarde est en cours, des chunks sont ajoutés au pool et leur refcount est incrémenté. Si la sauvegarde est interrompue (coupure réseau, arrêt du serveur, etc.), le pool peut se retrouver dans un état incohérent : des chunks présents dans le pool sans être référencés par aucune sauvegarde complète.
C'est la solution la plus complexe et qui a nécessité le plus de travail pour être implémentée de manière fiable. En effet, il faut s'assurer que le comptage de référence est bon si on ne veux pas se retrouver à éliminer des chunks encore référencés.
Afin de garantir que le comptage de référence est bon, un outil de récupération a été développé : il analyse le pool et les manifestes des sauvegardes, et corrige les refcounts en cas d'incohérence. Il n'est normallement nécessaire qu'en cas de crash du serveur (coupure de courant, etc.) pendant une sauvegarde.
Actuellement la structure du pool repose sur le système de fichiers. L'inconvénient est à aujourd'hui la durée d'execution du fsck qui peut être très longue (taille du pool). En échange les opérations de lecture/écriture sont très rapides.
Les BREAKING CHANGES
Par rapport à la version 1, on est sur une réécriture complète. Vu le peu de monde qui utilise cette version 1, il n'y a pas de migration prévue. La version 2 est un nouveau projet, avec une nouvelle API, et des changements majeurs dans la façon dont les sauvegardes sont gérées.
Windows sans rsync : binaire natif cross-compilé
Dans la version 1, le client Windows était un serveur rsyncd couplé à Cygwin. C'était fonctionnel, mais peu élégant, difficile à installer, et les permissions NTFS n'étaient pas correctement sauvegardées.
Dans la version 2, le client Windows est un binaire Rust compilé en cross-compilation depuis Linux avec la cible
x86_64-pc-windows-msvc et le linker LLVM/Clang. Le binaire est distribué seul, sans dépendance. Il se connecte au
serveur de sauvegarde via gRPC mTLS, crée un snapshot VSS, parcourt le système de fichiers et envoie les chunks.
Les ACLs NTFS, les attributs étendus, les points de jonction et les liens symboliques Windows sont correctement gérés. C'est un vrai progrès.
La sécurité : mTLS de bout en bout
Toutes les communications impliquant ws_client_daemon sont chiffrées et authentifiées par mutual TLS (mTLS).
Chaque périphérique possède un certificat client signé par une autorité de certification interne au serveur Woodstock.
Deux canaux mTLS distincts :
job_worker↔ws_client_daemon(gRPC) : le canal de sauvegarde, à l'initiative du serveur.ws_client_daemon→client_api_server(REST) : le canal de présence, à l'initiative du client, qui lui permet de signaler son statut online/offline.
Cela garantit que :
- Les données sauvegardées sont chiffrées en transit.
- Seul le serveur Woodstock peut déclencher une sauvegarde sur un périphérique enregistré.
- Un périphérique ne peut pas usurper l'identité d'un autre.
À noter : api_server, qui sert l'interface Vue.js, ne dispose pas encore d'authentification. C'est prévu, mais pas encore fait (voir plus bas).
En production depuis plus d'un an
Les machines sauvegardées
Voici un tableau récapitulatif de mes neuf machines sauvegardées au 26 avril 2026 :
| Machine | Rôle | Sauvegardes | Fichiers | Taille brute | Compressé |
|---|---|---|---|---|---|
localhost | NAS local (Debian) | 43 | 13 346 | 1,3 Go | 0,8 Go |
pc-eve | PC principal de la famille (Windows) | 211 | 563 333 | 473 Go | 413 Go |
pc-m-eve | Ordinateur portable familial (Windows) | 26 | 146 243 | 21,6 Go | 13,5 Go |
pc-m-ulrich | Mon portable personnel (Linux) | 53 | 43 185 | 125 Go | 64,5 Go |
pc-ulrich | Mon PC de bureau (Linux) | 322 | 1 385 001 | 108 Go | 76,7 Go |
pc-alex-linux | PC Linux secondaire | 4 | 210 006 | 25 Go | 14,5 Go |
pc-alex-windows | PC Windows secondaire | 360 | 429 368 | 147 Go | 108 Go |
server | Serveur dédié OVH principal | 450 | 243 074 | 810 Go | 752 Go |
server-ovh-6 | Second serveur OVH | 472 | 493 441 | 194 Go | 173 Go |
Quelques observations :
serveretserver-ovh-6ont le plus grand nombre de sauvegardes (450 et 472). Ce sont des serveurs qui tournent 24/7, avec des données critiques.pc-ulrichcumule plus de 1,3 million de fichiers sauvegardés, ce qui en fait la machine avec le plus grand nombre de fichiers individuels. Mon répertoire de développement est manifestement très fragmenté. 😄- La compression Zstd est particulièrement efficace sur
pc-m-ulrich(49 % d'économie) et beaucoup moins surserver(7 %), ce qui s'explique par la nature des données stockées : données de développement vs. données déjà compressées (archives, images Docker, etc.).
Le pool global
Le pool CAS central agrège toutes les sauvegardes :
| Statistique | Valeur |
|---|---|
| Chunks uniques | 3 365 564 |
| Références totales | 60 888 193 |
| Espace pool compressé | 1,95 To |
| Espace disque total | 9,6 To |
| Espace disque utilisé | 6,4 To |
Le ratio références/chunks (60,9 M / 3,4 M ≈ 18x) illustre l'efficacité de la déduplication : chaque chunk unique est en moyenne référencé 18 fois par différentes sauvegardes. L'historique long des sauvegardes explique cette valeur élevée.
Interface web
L'interface web Vue.js 3 / Vuetify permet de visualiser l'état de l'infrastructure, du pool, et de l'historique des sauvegardes de chaque machine.
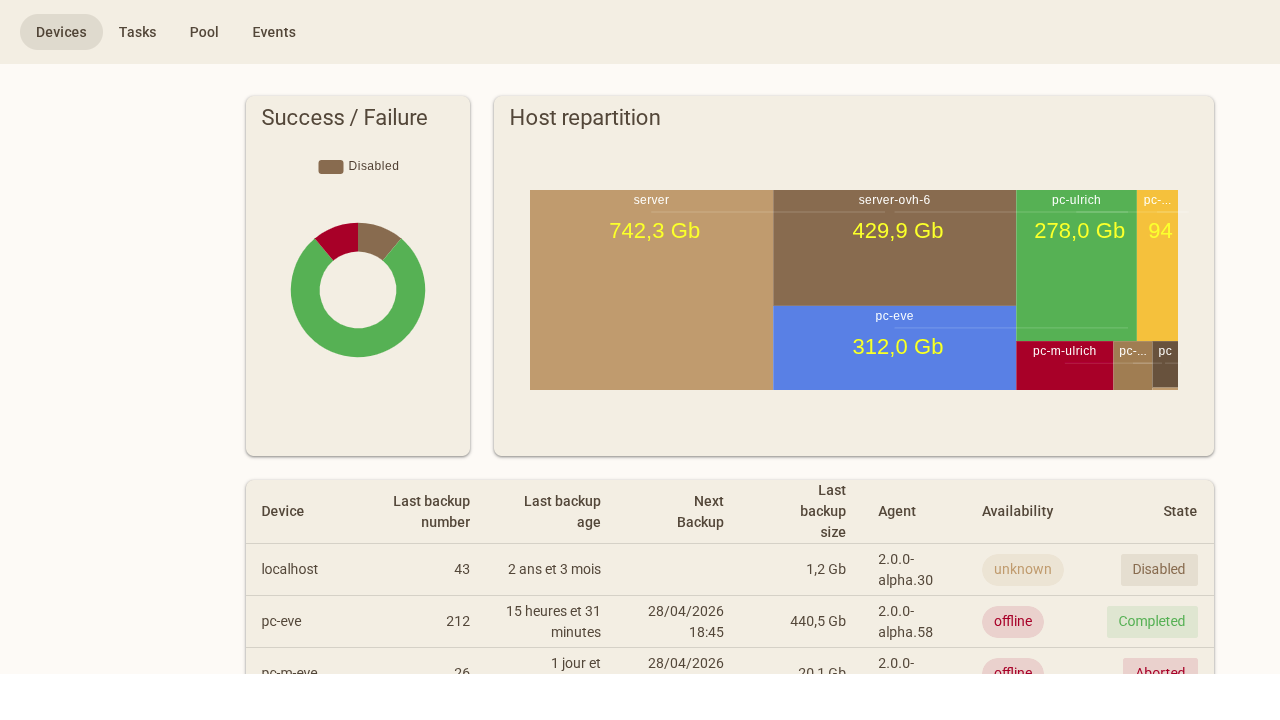
La page principale liste les neuf machines avec leur état, le nombre de sauvegardes, la taille brute et compressée.
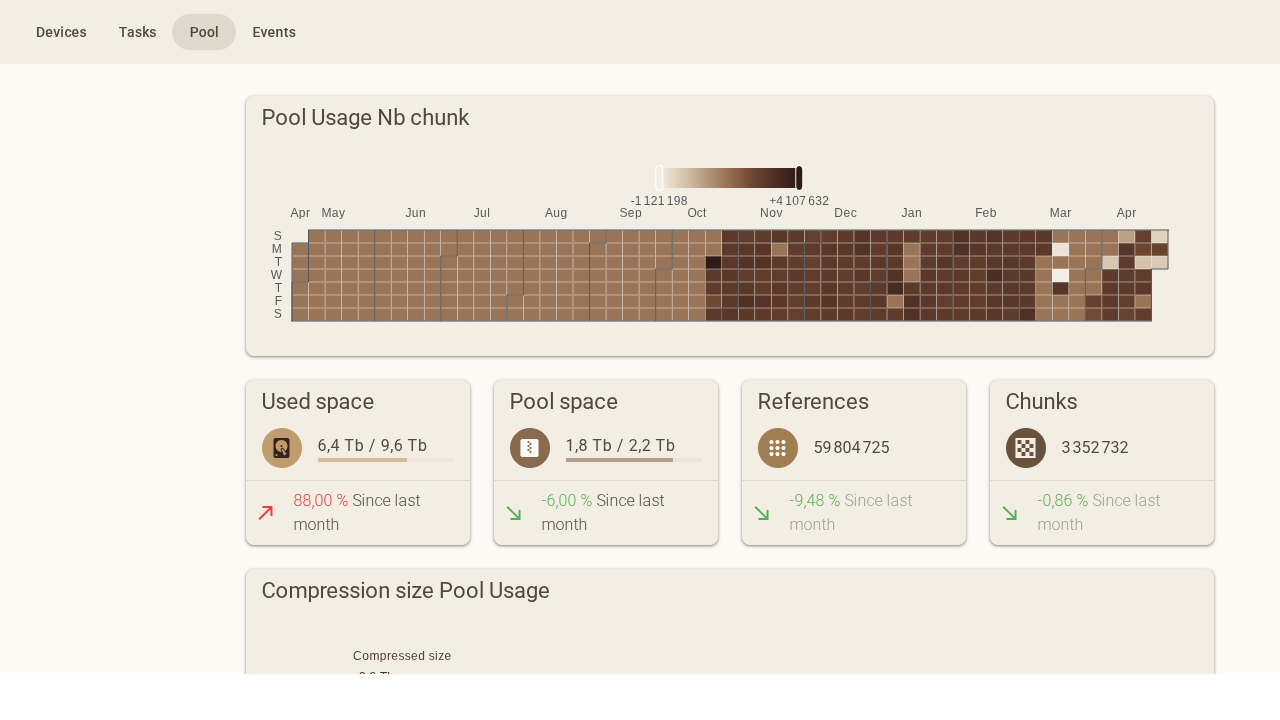
La page pool affiche les statistiques globales du stockage : occupation disque, nombre de chunks, nombre de références, et l'évolution depuis le mois précédent.
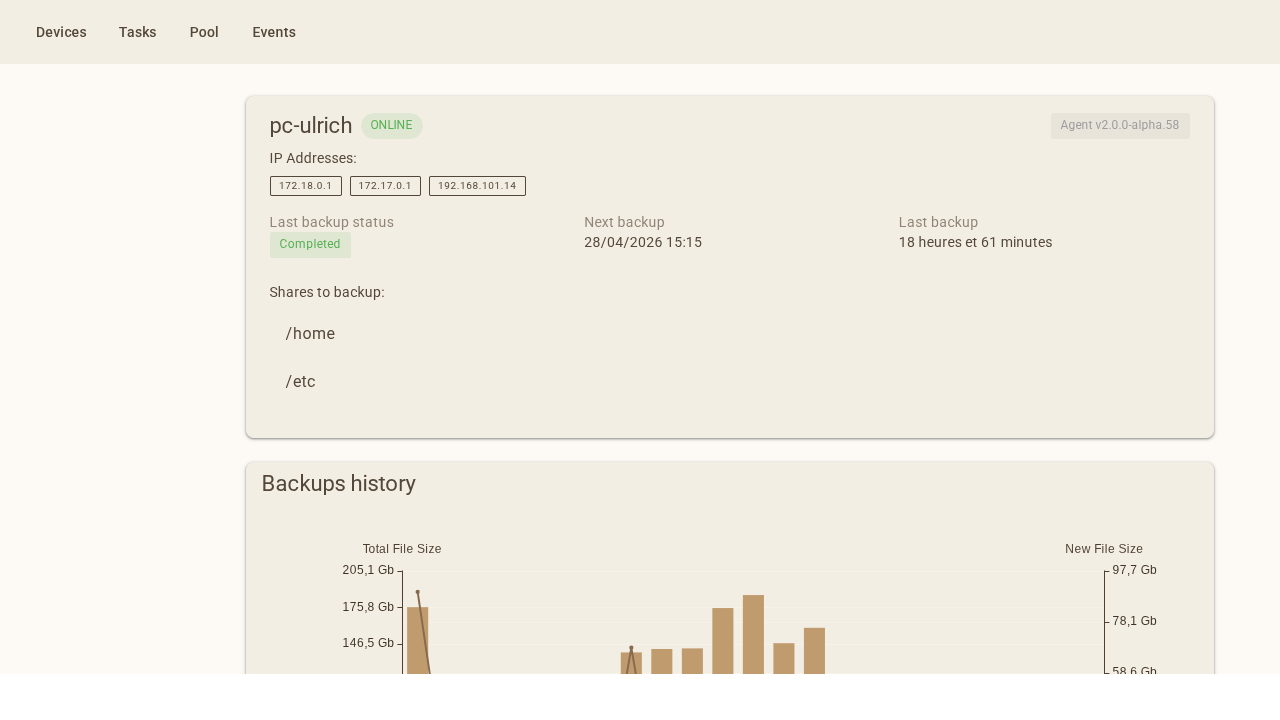
La page de détail d'une machine liste l'historique complet de ses sauvegardes avec la date, la durée, et la liste des partitions sauvegardées.
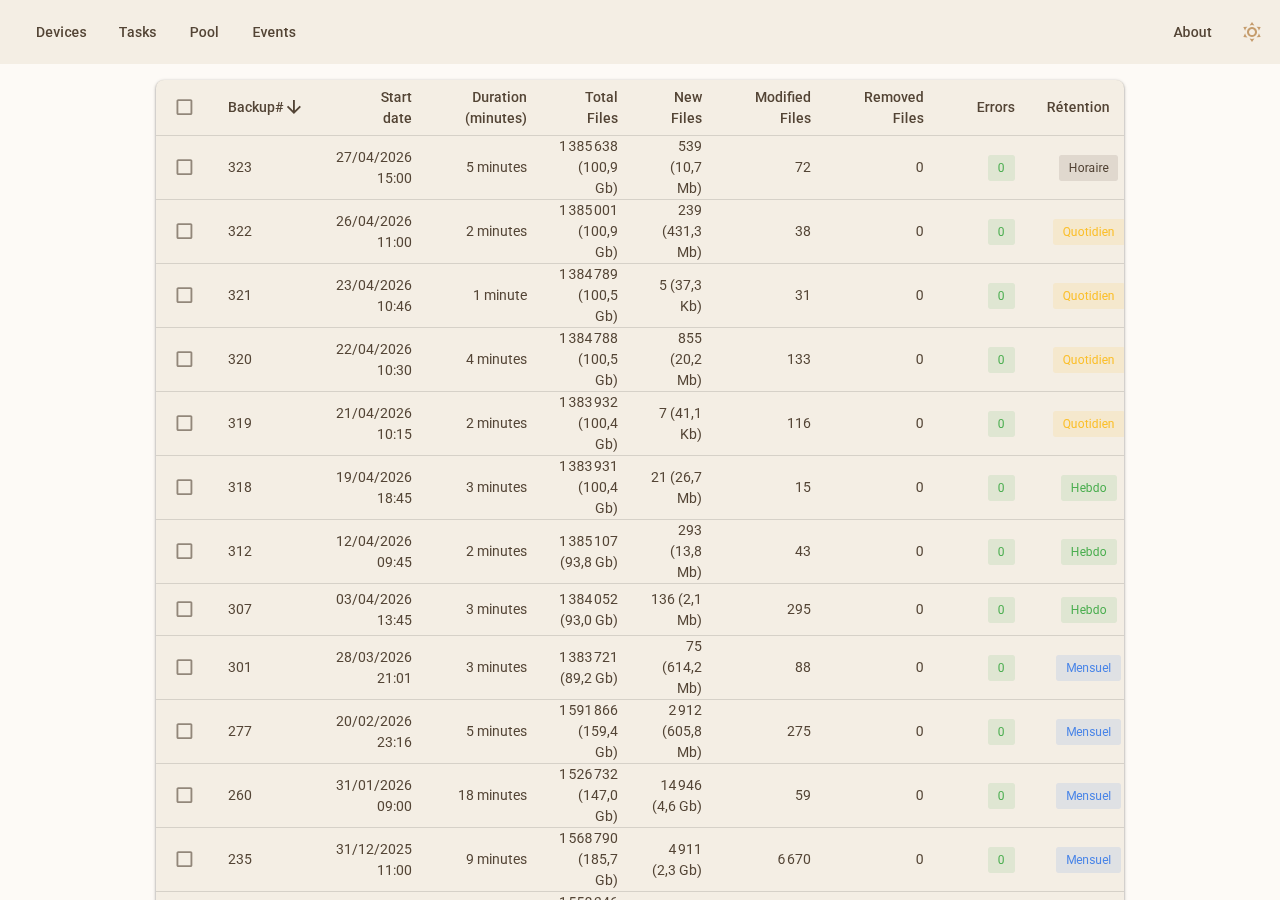
Chaque entrée de la liste indique le numéro de sauvegarde, la date de démarrage, la durée, le nombre de fichiers totaux et nouveaux, les fichiers modifiés et supprimés, le compteur d'erreurs, et la politique de rétention appliquée : Horaire, Quotidien, Hebdo ou Mensuel.
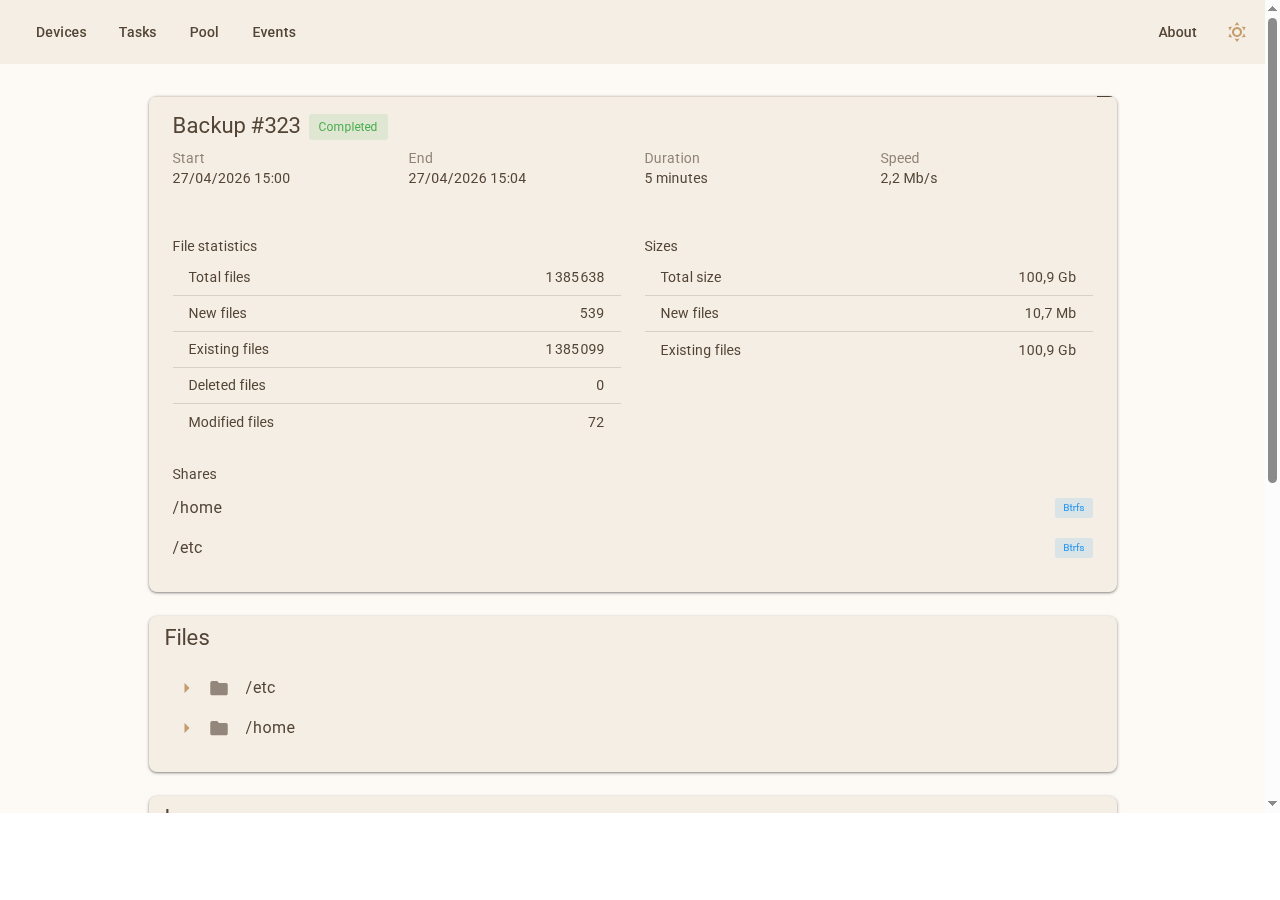
En cliquant sur une sauvegarde, on accède à la vue détaillée : statistiques complètes (fichiers, tailles, durée, vitesse), partitions sauvegardées avec leur type (Btrfs ou VSS), et un explorateur de fichiers permettant de naviguer dans l'arborescence et de télécharger ou restaurer individuellement n'importe quel fichier.
Perspectives
Archivage hors-site sur disque USB
Une fonctionnalité que je veux mettre en place depuis la v1 est l'archivage de la dernière version des sauvegardes sur un disque dur USB, qui est ensuite stocké hors-site. L'idée est d'avoir une copie physique des données dans un autre lieu en cas de sinistre (incendie, vol, etc.).
Dans la version 1 avec BackupPC, j'avais un script qui utilisait le connecteur FUSE de BackupPC pour monter les sauvegardes et les synchroniser avec rsync vers le disque USB. Ce script posait des problèmes avec les gros fichiers et les permissions Windows, comme je l'avais mentionné dans le tout premier article.
Dans Woodstock v2, l'outil en ligne de commande ws_console dispose d'une commande mount qui permet de monter
une sauvegarde comme un système de fichiers FUSE. Il sera donc possible de faire un rsync depuis ce point de
montage vers le disque USB, avec une gestion correcte des permissions et des gros fichiers.
Ce n'est pas encore automatisé, mais c'est la prochaine chose que je veux mettre en place.
Ajout d'un format de stockage
J'envisage également de pouvoir stocker directement le pool sur un bucket S3 ou compatible (SeaweedFS, RustFS). Avant de me lancer dans cette implémentation, je veux d'abord tester les performances d'un tel choix.
Comparaison avec les solutions existantes
Avant de conclure, voici une comparaison honnête avec les alternatives réalistes. Si un autre outil correspond mieux à vos besoins, utilisez-le. Sans rancune.
Les outils couverts : Restic, BorgBackup, BackupPC, URBackup et Kopia. Ils représentent les principales solutions open-source pour une infrastructure self-hostée multi-machines — ce qui correspond grosso modo au problème que Woodstock cherche à résoudre.
| Critère | Woodstock v2 | Restic | BorgBackup | BackupPC | URBackup | Kopia |
|---|---|---|---|---|---|---|
| Langage | Rust | Go | Python + C | Perl | C++ | Go |
| Licence | MIT | BSD-2 | BSD | GPL v2+ | AGPLv3+ | Apache 2.0 |
| Développement actif | ✅ 2026 | ✅ 2025 | ✅ 2026 | ❌ 2020¹ | ✅ 2026 | ✅ 2025 |
| Modèle de synchronisation | Pull (initié par le serveur) | Push (le client pousse) | Push (SSH ou local) | Pull (rsync/tar/SMB) | Pull-like (découverte LAN) | Push / mode serveur |
| Agent requis sur le client | daemon | N'a pas de sens | N'a pas de sens | rsync | daemon | serveur optionnel |
| Backends cloud/distants | ❌ self-hosted uniquement | ✅ S3, B2, SFTP, Azure, GCS, rclone… | ⚠️ SSH / BorgBase | ❌ disque local uniquement | ❌ self-hosted uniquement | ✅ S3, Azure, GCS, B2, SFTP, rclone… |
| Format de stockage | Pool CAS, fichiers sur disque | Pack files CAS | Journal de segments + index | Pool MD5 (niveau fichier) + reverse deltas | Snapshots de fichiers + images de blocs | Pack files CAS |
| Granularité de déduplication | Chunk (CDC) | Chunk (CDC) | Chunk (BUZHASH CDC) | Fichier (MD5 fichier complet, sans hardlinks en v4) | Fichier | Chunk (CDC) |
| Dédup cross-machines | ✅ (un pool partagé) | ⚠️ uniquement si dépôt partagé | ⚠️ uniquement au sein d'un dépôt | ✅ (pool MD5 partagé) | ✅ (niveau fichier) | ⚠️ uniquement au sein d'un dépôt |
| Chiffrement au repos | ❌ pool en clair | ✅ pool chiffré | ✅ pool chiffré (optionnel) | ❌ pool en clair | ❌ pool en clair | ✅ pool chiffré (optionnel) |
| Linux | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| macOS | ❌² | ✅ | ✅ | ✅ | ✅ | ✅ |
| Windows (natif) | ✅ (binaire MSVC) | ✅ | ❌ (WSL2 uniquement) | ⚠️ (rsync/Cygwin ou SMB) | ✅ | ✅ |
| Snapshots VSS (Windows) | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ |
| Snapshots Btrfs (Linux) | ✅ | ❌ (hooks manuels) | ❌ (hooks manuels) | ❌ | ❌ | ❌ |
| Sauvegarde image / bare-metal | ❌ | ❌ | ❌ | ❌ | ✅ (Windows + Linux) | ❌ |
| Montage FUSE | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| Interface web | ✅ (sans auth pour l'instant) | ❌ (tiers : Restic Browser) | ❌ (tiers : Vorta) | ✅ (CGI/Perl) | ✅ | ✅ (KopiaUI) |
¹ La dernière version de BackupPC date de juin 2020. La base de code est stable mais n'est plus maintenue.
² La prise en charge de macOS n'est pas encore implémentée dans Woodstock.
Quelques points à souligner :
Le modèle pull (Woodstock, BackupPC, URBackup) signifie qu'un client compromis ne peut pas écrire de données arbitraires sur le serveur de sauvegarde. Le modèle push (Restic, Borg, Kopia) est plus simple à mettre en place, mais accorde davantage de confiance à chaque client.
La déduplication au niveau des chunks signifie que si un fichier de 10 Go est modifié d'1 Mo, seul cet 1 Mo est transféré et stocké (si la taille du chunk est de 1Ko - sur Woodstock la taille du chunk est de 16Mo). La déduplication au niveau fichier (BackupPC, URBackup) signifie que si un fichier change, le nouveau fichier entier est stocké dans le pool. Pour BackupPC spécifiquement, rsync gère le transfert de manière efficiente — seuls les blocs modifiés transitent sur le réseau — mais comme la correspondance dans le pool est basée sur un MD5 du fichier complet, un fichier modifié génère toujours une nouvelle entrée complète dans le pool.
La déduplication cross-machines est moins courante. Si dix machines possèdent chacune une copie du même installeur de 500 Mo, Woodstock ne le stocke qu'une seule fois. Restic et Borg ne dédupliquent qu'au sein d'un même dépôt — pour obtenir une déduplication cross-machines, il faudrait mettre toutes les machines dans le même dépôt, ce qui crée des problèmes de contention de verrous et de contrôle d'accès.
La principale faiblesse de Woodstock : le pool n'est pas chiffré au repos. Si quelqu'un obtient un accès physique ou système à votre NAS, il peut lire vos données de sauvegarde directement. L'approche de Restic — tout chiffrer, de manière obligatoire — est clairement plus solide si quelqu'un met la main sur votre disque. Sur un NAS de LAN privé que vous contrôlez physiquement, c'est un compromis que j'accepte. Pour un stockage distant ou dans le cloud, c'est une vraie limitation. Il est possible de contrer ce problème en chiffrant le disque lui-même (LUKS, BitLocker, etc.), mais c'est une couche supplémentaire à gérer.
Si vous avez besoin d'une restauration bare-metal, URBackup est le seul outil de cette liste qui le fait nativement. Si vous avez besoin de BorgBackup sur Windows, c'est impossible sans WSL2.
Conclusion
Ce projet m'a appris énormément de choses : Rust, gRPC, mTLS, la gestion de pools CAS, le VSS Windows, les snapshots Btrfs, la gestion de jobs distribués avec Redis, et probablement une dizaine d'autres sujets que j'ai oubliés depuis.
Est-ce que c'était raisonnable de passer six ans à construire son propre logiciel de sauvegarde alors qu'il en existe des dizaines ? Bien sur que oui 😄.
Le logiciel est disponible sur mon instance Gitea et la documentation est sur woodstock.shadoware.org.
À bientôt !